По мере того, как вы продвигаетесь по карьерной лестнице в качестве разработчика, вам нужно будет все больше и больше думать об архитектуре программного обеспечения и проектировании систем. Важно уметь разрабатывать эффективные системы и идти на компромисс в масштабах. Системное проектирование — это обширная область, которая включает в себя множество важных концепций. Фундаментальной концепцией системного проектирования является теорема CAP. Понимание теоремы CAP является ключом к пониманию того, как проектировать сильные распределенные системы. Сегодня мы углубимся в теорему CAP, объясняя ее значение, ее компоненты и многое другое.
Содержание
- Что такое теорема CAP?
- Доказательство теоремы CAP
- Объяснение согласованности, доступности и допустимости разделов
- Последовательность
- Доступность
- Допуск на разделение
- CAP-теорема NoSQL базы данных
- Базы данных CA
- Базы данных CP
- Базы данных AP
- Теорема CAP и микросервисы
- Подведение итогов и следующие шаги
Что такое теорема CAP?
Теорема CAP, или теорема Брюера, является фундаментальной теоремой в области проектирования систем. Впервые он был представлен в 2000 году Эриком Брюером, профессором информатики в Калифорнийском университете в Беркли, во время выступления о принципах распределенных вычислений. В 2002 году профессора Массачусетского технологического института Нэнси Линч и Сет Гилберт опубликовали доказательство гипотезы Брюера. Теорема CAP утверждает, что распределенная система может одновременно обеспечивать только два из трех свойств: согласованность, доступность и устойчивость к разделению. Теорема формализует компромисс между согласованностью и доступностью при наличии раздела.
Распределенная система — это совокупность компьютеров, которые работают вместе, образуя единый компьютер для конечных пользователей. Все распределенные машины имеют одно общее состояние и работают одновременно. В распределенных системах пользователи должны иметь возможность связываться с любой из распределенных машин, не зная, что это только одна машина. Сеть распределенной системы хранит свои данные не только на одном узле, но и на нескольких физических или виртуальных машинах одновременно.
Доказательство теоремы CAP
Давайте посмотрим на простое доказательство теоремы CAP. Представьте себе распределенную систему, состоящую из двух узлов:
Распределенная система действует как обычный регистр со значением переменной X. Произошел сетевой сбой, который приводит к разделению сети между двумя узлами в системе. Конечный пользователь выполняет запрос записи, а затем запрос чтения. Давайте рассмотрим случай, когда каждый запрос обрабатывает другой узел системы. В этом случае у нашей системы есть два варианта:
- Может выйти из строя по одному из запросов, нарушив доступность системы
- Он может выполнять оба запроса, возвращая устаревшее значение из запроса на чтение и нарушая согласованность системы.
Система не может успешно обработать оба запроса, одновременно гарантируя, что чтение возвращает последнее значение, записанное при записи. Это связано с тем, что результаты операции записи не могут быть переданы с узла A на узел B из-за сетевого раздела.
Объяснение согласованности, доступности и допустимости разделов
Теперь, когда у нас есть базовое понимание теоремы CAP, давайте разберемся с аббревиатурой и обсудим значения согласованности, доступности и допустимости разделов.
Последовательность
В согласованной системе все узлы одновременно видят одни и те же данные. Если мы выполняем операцию чтения в согласованной системе, она должна возвращать значение самой последней операции записи. При чтении все узлы должны возвращать одни и те же данные. Все пользователи видят одни и те же данные одновременно, независимо от узла, к которому они подключены. Когда данные записываются на один узел, они затем реплицируются на другие узлы в системе.
Доступность
Когда доступность присутствует в распределенной системе, это означает, что система остается работоспособной все время. На каждый запрос будет получен ответ независимо от индивидуального состояния узлов. Это означает, что система будет работать, даже если несколько узлов не работают. В отличие от согласованной системы, нет гарантии, что ответ будет самой последней операцией записи.
Допуск на разделение
Когда распределенная система встречает раздел, это означает разрыв связи между узлами. Если система терпима к разделам, система не откажет, независимо от того, отбрасываются ли сообщения или задерживаются между узлами внутри системы. Чтобы иметь допуск к разделению, система должна реплицировать записи по комбинациям узлов и сетей.
CAP-теорема NoSQL базы данных
Базы данных NoSQL отлично подходят для распределенных сетей. Они позволяют горизонтальное масштабирование и могут быстро масштабироваться на нескольких узлах. Решая, какую базу данных NoSQL использовать, важно помнить о теореме CAP. NoSQL базы данных можно классифицировать на основе двух поддерживаемых ими функций CAP:
Базы данных CA
Базы данных CA обеспечивают согласованность и доступность на всех узлах. К сожалению, базы данных CA не могут обеспечить отказоустойчивость. В любой распределенной системе разделы неизбежны, а это означает, что этот тип базы данных не очень практичный выбор. При этом вы все равно можете найти базу данных CA, если она вам нужна. Некоторые реляционные базы данных, такие как PostgreSQL, обеспечивают согласованность и доступность. Вы можете развернуть их на узлах с помощью репликации.
Базы данных CP
Базы данных CP обеспечивают согласованность и устойчивость к разделам, но не доступность. Когда происходит разделение, система должна отключить несогласованные узлы, пока раздел не будет исправлен. MongoDB — это пример базы данных CP. Это система управления базами данных (СУБД) NoSQL, которая использует документы для хранения данных. Считается, что он не имеет схемы, что означает, что для него не требуется определенная схема базы данных. Он обычно используется в больших данных и приложениях, работающих в разных местах. Система CP структурирована так, что есть только один первичный узел, который получает все запросы на запись в данном наборе реплик. Вторичные узлы реплицируют данные в первичных узлах, поэтому в случае отказа первичного узла вторичный узел может заменить.
Базы данных AP
Базы данных AP обеспечивают доступность и устойчивость к разделам, но не согласованность. В случае раздела доступны все узлы, но не все они обновлены. Например, если пользователь пытается получить доступ к данным с неисправного узла, он не получит самую последнюю версию данных. Когда раздел в конечном итоге будет разрешен, большинство баз данных AP синхронизируют узлы для обеспечения согласованности между ними. Apache Cassandra — это пример базы данных AP. Это база данных NoSQL без первичного узла, что означает, что все узлы остаются доступными. Cassandra обеспечивает возможную согласованность, потому что пользователи могут повторно синхронизировать свои данные сразу после разрешения раздела.
Теорема CAP и микросервисы
Микросервисы определяются как слабо связанные сервисы, которые можно независимо разрабатывать, развертывать и поддерживать. Они включают свой собственный стек, базу данных и модель базы данных и обмениваются данными друг с другом через сеть. Микросервисы стали особенно популярными в гибридных облачных и мультиоблачных средах. А также широко используются в локальных центрах обработки данных. Если вы хотите создать приложение для микросервисов, вы можете использовать теорему CAP, чтобы помочь вам определить базу данных, которая наилучшим образом соответствует вашим потребностям.
Подведение итогов и следующие шаги
Поздравляем с тем, что вы сделали первый шаг в изучении теоремы CAP и распределенных систем! Распределенные системы обеспечивают меньшую задержку, масштабируемость, повышенную взаимосвязь и многое другое. Теорема CAP очень важна для распределенных систем и системного проектирования в целом. Сегодня мы многое рассмотрели, но еще многое предстоит узнать о распределенных системах. Вот некоторые рекомендуемые темы для дальнейшего изучения:
- Распределенные хранилища данных
- Алгоритмы распределенной системы
- Атомарность
Learn the fundamentals of the CAP theorem, how it comes into play with microservices and what it means for your distributed architecture design choices.
It’s not unusual for developers and architects who jump into microservices for the first time to «want it all» in terms of performance, uptime and resiliency. After all, these are the goals that drive a software team’s decision to pursue this type of architecture design. The unfortunate truth is that trying to create an application that perfectly embodies all of these traits will eventually steer them to failure.
This phenomenon is summed up in something called the CAP theorem, which states that a distributed system can deliver only two of the three overarching goals of microservices design: consistency, availability and partition tolerance. According to CAP, not only is it impossible to «have it all» — you may even struggle to deliver more than one of these qualities at a time.
When it comes to microservices, the CAP theorem seems to pose an unsolvable problem. Which of these three things can you afford to trade away? However, the essential point is that you don’t have a choice. You’ll have to face that fact when it comes to your design stage, and you’ll need to think carefully about the type of application you’re building, as well as its most essential needs.
In this article, we’ll review the basics of how the CAP theorem applies to microservices, and then examine the concepts and guidelines you can follow when it’s time to make a decision.
CAP theory and microservices
Let’s start by reviewing the three qualities CAP specifically refers to:
- Consistency means that all clients see the same data at the same time, no matter the path of their request. This is critical for applications that do frequent updates.
- Availability means that all functioning application components will return a valid response, even if they are down. This is particularly important if an application’s user population has a low tolerance for outages (such as a retail portal).
- Partition tolerance means that the application will operate even during a network failure that results in lost or delayed messages between services. This comes into play for applications that integrate with a large number of distributed, independent components.
When it comes to microservices, the CAP theorem seems to pose an unsolvable problem.
Databases often sit at the center of the CAP problem. Microservices often rely on NoSQL databases, since they’re designed to scale horizontally and support distributed application processes. And, partition tolerance is a «must have» in these types of systems because they are so sensitive to failure.
You can certainly design these kinds of databases for consistency and partition tolerance, or even for availability and partitioning. But designing for consistency and availability just isn’t an option.
The PACELC theorem
This prohibitive requirement for partition-tolerance in distributed systems gave rise to what is known as the PACELC theorem, a sibling to the CAP theorem. The acronym PACELC stands for «if partitioned, then availability and consistency; else, latency and consistency.» In other words: If there is a partition, the distributed system must trade availability for consistency; if not, the choice is between latency and consistency.
Designing your applications specifically to avoid partitioning problems in a distributed system will force you to sacrifice either availability or user experience to retain operational consistency. However, the key term here is «operational» — while latency is a primary concern during normal operations, a failure can quickly make availability the overall priority. So, why not create models for both scenarios?
It may help to frame CAP concepts in both «normal» and «fault» modes, provided that faults in a distributed system are essentially inevitable. This enables you to create two database and microservices implementation models: one that handles normal operation, and another that kicks in during failures. For example, you can design your database to optimize consistency during a partition failure, and then continue to focus on mitigating latency during normal operation.
Applying PACELC to microservices
If we use PACELC rather than «pure CAP» to define databases, we can classify them according to how they make the trades.
- In PACELC terms, relational database management systems and NoSQL databases that implement ACID (atomicity, consistency, isolation, urability) are designed to assure consistency, classifying them as PC/EC. Typical business applications, like human resources apps and ticketing systems, will likely use this model, particularly if there are multiple users using different component instances. Google’s Bigtable database is a good example of this.
- In-memory databases like MongoDB and Hazelcast fit into a PA/EC model, which is best suited for things like e-commerce apps, which need high availability even during network or component failures.
- Real-time applications, such as IoT systems, fit into the PC/EL model that databases like PNUTS provide. This is the case in any application where consistency across replications is critical.
- Database systems based on the PA/EL model, such as Dynamo and Cassandra, are best for real-time applications that don’t experience frequent updates, since consistency will be less of an issue.
Know the tradeoffs
The bottom line is this: It’s critical to know exactly what you’re trading in a PACELC-guided application, and to know which scenarios call for which sacrifice. Here are three things to remember when making your decision:
- Consistency is most valuable where many users update the same data elements.
- Availability is critical for applications involving consumers (who get frustrated easily) and also for some IoT applications.
- Latency is most likely critical for real-time and IoT applications where processing delays must be kept to a minimum.
Make your database choice wisely. Then, design your microservices workflows and framework to ensure you don’t compromise your goals.
Dig Deeper on Enterprise architecture management
-

analog-to-digital conversion (ADC)
By: Paul Kirvan
-
Can you really use a shared database for microservices?
By: Priyank Gupta
-
Nyquist theorem
By: Gavin Wright
-
Google Cloud Spanner
By: Jack Vaughan







Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Microservices are a distributed system so CAP Theorem must apply right? Well, that depends on how you define microservices and a distributed system! Microservices are defined as “loosely coupled services oriented architecture with bounded context”. SOA implies Event Driven Architecture. If your microservices are loosely coupled, they aren’t making direct RPC calls to each other. If this is the case, then there are no partitions that can occur between services. If services are a bounded context and own their own data, then there is no consistency between services.
CAP does not apply to Microservices if they are loosely coupled and are a bounded context.
Here’s a breakdown and to further explain why the question “Does CAP Theorem apply to Microservices?” doesn’t even make sense and has no relation to Microservices.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
In theoretical computer science, the CAP theorem, also named Brewer’s theorem after computer scientist Eric Brewer, states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
Consistency: Every read receives the most recent write or an error
Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
When a network partition failure happens should we decide toCancel the operation and thus decrease the availability but ensure consistency
Proceed with the operation and thus provide availability but risk inconsistency
The CAP theorem implies that in the presence of a network partition, one has to choose between consistency and availability.https://en.wikipedia.org/wiki/CAP_theorem
An example I often see which explains CAP pretty well is the use case of an ATM. Let’s say there are 2 ATMs that communicate over the network. Anytime you go to deposit money into an ATM, it confirms the other ATM is online and available.
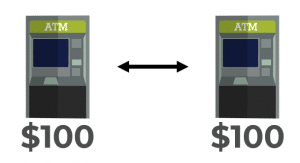
If both ATMs are online and available and you make a deposit of $100, both ATMs will have recorded that deposit. If you go to the other ATM and check your balance it will be $100. Both ATMs are consistent.
When a network partition occurs, we must choose consistency or availability.
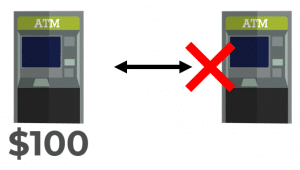
If we choose consistency, then if we cannot communicate between ATMs, then we cannot allow a deposit at one ATM because it will not be consistent with the other ATM.
If we choose availability, then we will allow the deposit to occur, however, if we go to the other ATM, it won’t be aware of our $100 deposit. Our system would have to reconcile the differences between ATMs when they are able to communicate.
So back to the question: Does CAP Theorem apply to Microservices? Well, what’s the definition of Microservices?
Microservices
Adrian Cockcroft defined Microservices as:
loosely coupled service oriented architecture with bounded contexts
https://www.slideshare.net/adriancockcroft/dockercon-state-of-the-art-in-microservices
This is very different than a distributed system where each node provides the same capabilities and data. Microservices are about the decomposition of a larger system. Each microservice has its own behavior and its own data. Comparing the two systems are like comparing apples and oranges.
But there are two key points that I’d like to talk about in Adrian’s definition that really drive this home. Loosely coupled and bounded context.
Bounded Context
The concept of a bounded context from Domain Driven Design is about creating a boundary. Adrian says:
If you have to know too much about surrounding services you don’t have a bounded context.
This is because concepts should be owned by a particular bounded context within a subdomain. One service shouldn’t have to know explicitly about the details of other services. Services are about defining business capabilities and the data behind those capabilities.
This is very different from the ATM example because again, each service is defining its own capabilities (functionality). With these capabilities is data ownership. Data isn’t owned by multiple bounded contexts. Building services with high functional cohesion is key in defining service boundaries.
Loosely Coupled
Coupling can be thought of in two ways. Afferent and Efferent Coupling.
If you’re thinking about a module/class/project:
Afferent Coupling (Ca) is what other modules depend on it.
Efferent Coupling (Ce) is what other modules does it depend on.
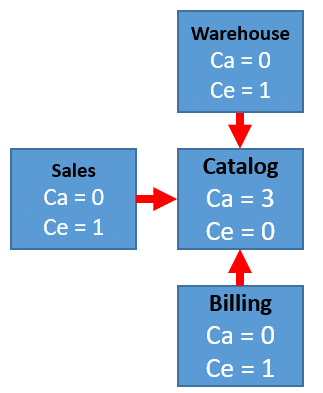
In this example, the Catalog module has an Afferent Coupling (Ca) of 3 because Warehouse, Sales, and Billing depend on it. The Catalog module has an Efferent Couling (Ce) of 0 because it depends on no other modules. Warehouse, Sales, and Billing all have an Afferent Coupling of 0 because no other module depends on them and an Efferent Coupling of 1 because they all depend on the Catalog.
If your modules are communicating in-process (monolith) over the network via an HTTP, they are still tightly coupled. Again, communicating via a REST HTTP API does not make your services less coupled or loosely coupled. This simply makes your system a distributed monolith.
What is loose coupling?
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components. Subareas include the coupling of classes, interfaces, data, and services. Loose coupling is the opposite of tight coupling.
https://en.wikipedia.org/wiki/Loose_coupling
If you think back to Adrian’s comment about a bounded context, about knowing too much, this is what he’s referring to. A way to achieve loose coupling is through a Message or Event Driven Architecture.
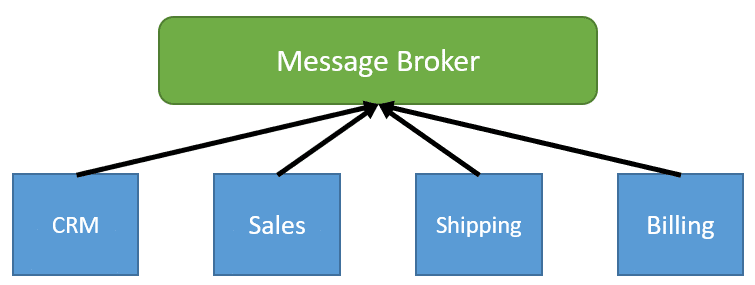
Instead of our services communicating directly with other services, we are sending and publishing events to a message broker. Each module consumes Events and reacts to them. The publisher of the events is totally unaware of who the consumers are or if there are any consumers at all.
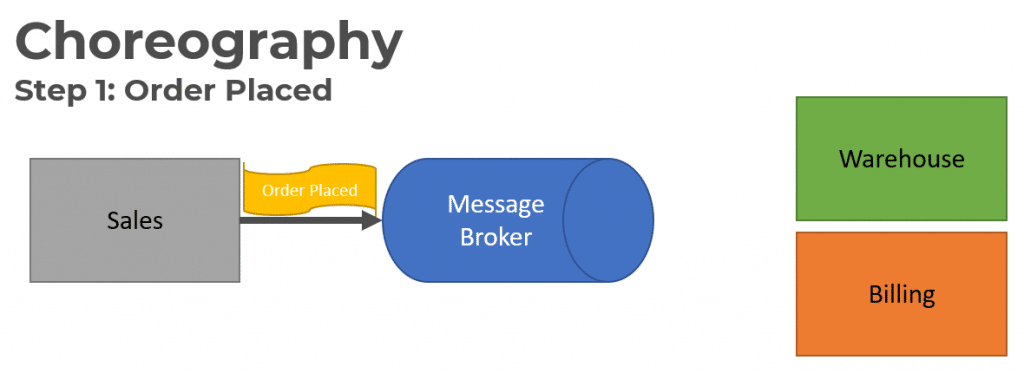
As an example in a long-running process of an e-commerce site of an order being placed, Event Choreography is used.
The first step is when an order is placed in the Sales service, an Order Placed Event is published to the message broker.
The Billing Service will consume that message and create an Invoice or Charge the customer.
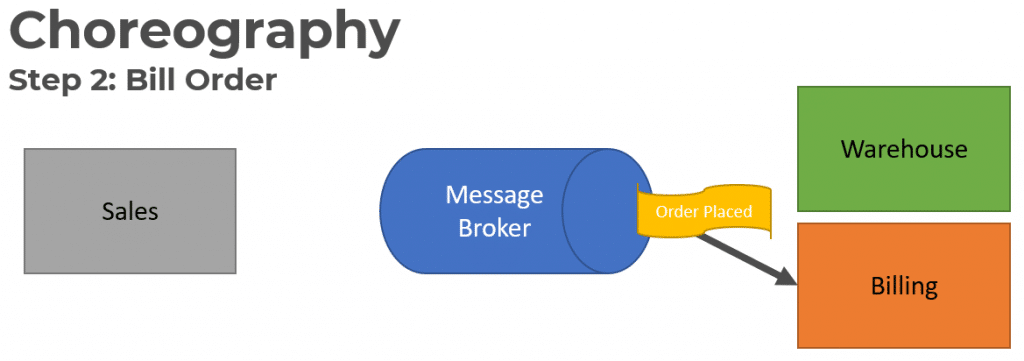
Once the Invoice or Customer has been charged the Billing service will publish an Order Billed event.
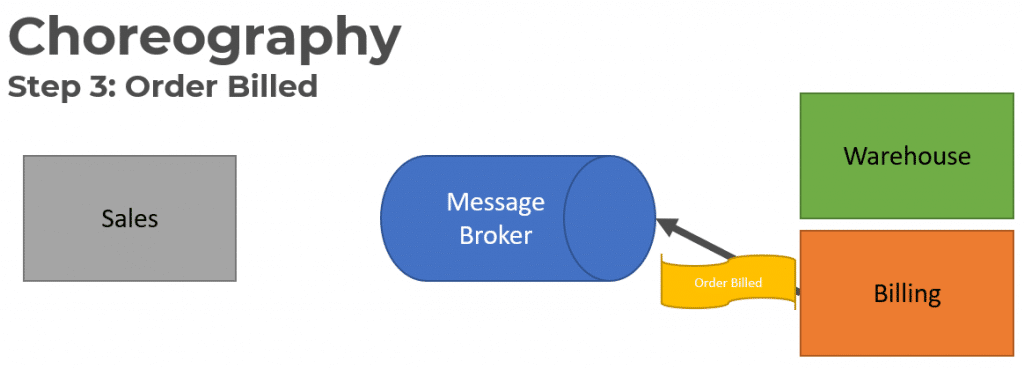
The Warehouse service will consume the Order Billed event in order to allocate product in the Warehouse.
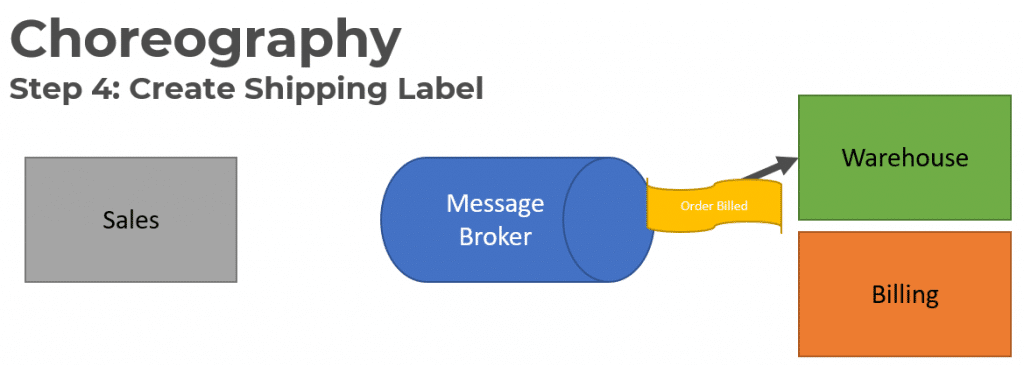
Once the product has been allocated and a shipping label has been created, it publishes a Shipping Label Created Event.
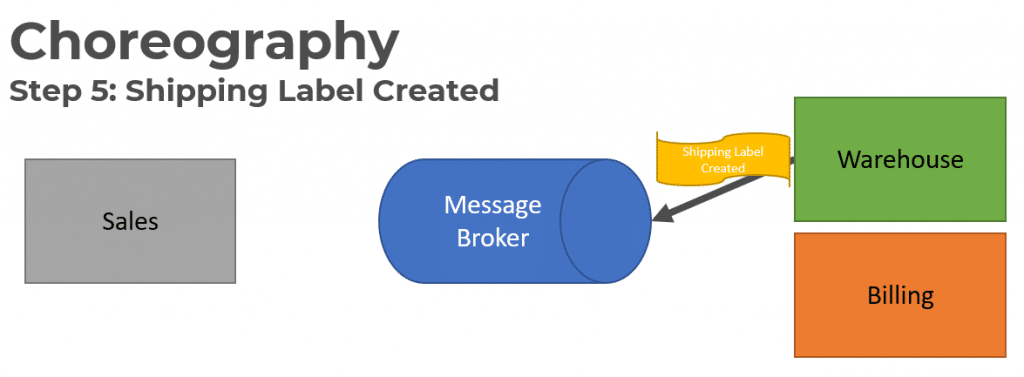
The Sales service consumes the Shipping Label Created event to update its Order Status.
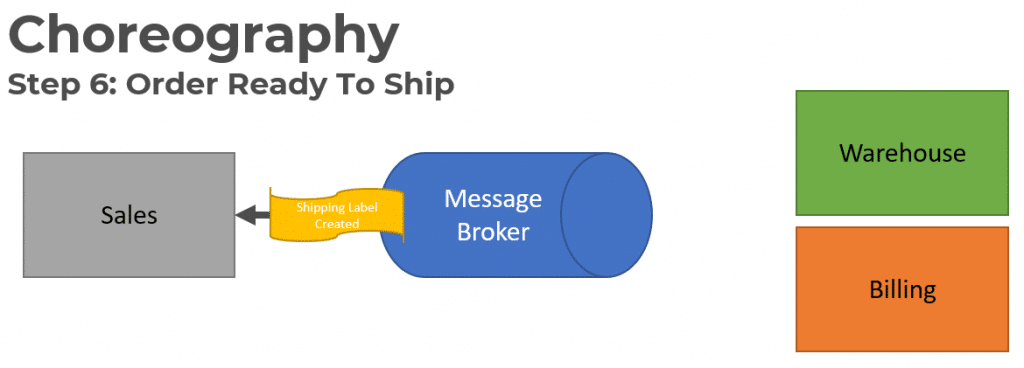
All of this workflow was done using Event Choregraphy. No service knew about the other services consuming the messages it was publishing. They are loosely coupled.
This means that Event Driven Architecture is a characteristic of a Microservices architecture.
For more on how this works for long-running business processes that span services can be managed check out my post on Event Choreography or Orchestration.
Does CAP Theorem apply to Microservices?
No. Absolutely not. Not when talking about Microservices as a part of a larger system.
Yes if you’re talking about the context of individual service. CAP can apply to individual service and if it chooses consistency or availability.
Services are about defining a set of business capabilities. Services do not share ownership over data. Services are loosely coupled through a Message and/or Event Driven Architecture.
There is no concern for consistency because there’s no data that needs to be consistent between services.
There is no concern for availability because each service is autonomous.
There is no concern for partition tolerance because each service is autonomous and loosely coupled.
Microservices are about the decomposition of a large system.
Related Posts
- Event Choreography & Orchestration (Sagas)
- Event Based Architecture: What do you mean by EVENT?
- CodeOpinion YouTube Channel
Follow @CodeOpinion on Twitter